So, why do we really care about state machine partitioning? Why can’t I have my big fatty FSM with 147 states if I want to?
Well, smaller state machines are:
- Easier to debug and probably less buggy
- More easily modified
- Require less decoding
- Are more suitable for low power applications
- Just nicer…
There is no rule of thumb stating the correct size of an FSM. Moreover, a lot of times it just doesn’t make sense to split the FSM – So when can we do it? or when should we do it? Part of the answer lies in a deeper analysis of the FSM itself, its transitions and most important, the probability of occupying specific states.
Look at the diagram below. After some (hypothetical) analysis we recognize that in certain modes of operation, we spend either a lot of time among the states marked in red or among the states marked in blue. Transitions between the red and blue areas are possible but are less frequent.
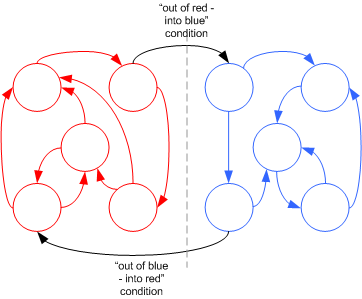
The trick now, is to look at the entire red zone as one state for a new “blue” FSM, and vice versa for the a new “red” FSM. We basically split the original FSM into two completely separate FSMs and add to each of the FSM a new state, which we will call a “wait state”. The diagram below depicts our new construction.

Notice how for the “red” FSM transitioning in and out of the new “wait state” is exactly equivalent (same conditions) to switching in and out of the red zone of the original FSM. Same goes for the blue FSM but the conditions for going in and out of the “wait state” are naturally reversed.
OK, so far so good, but what is this good for? For starters, it would probably be easier now to choose state encodings for each separate FSM that will reduce switching (check out this post on that subject). However, the sweetest thing is that when we are in the “red wait state” we could gate the clock for the rest of the red FSM and all its dependent logic! This is a significant bonus, since although previously such strategy would have been possible, it would just be by far more complicated to implement. The price we pay is additional states which will sometimes lead to more flip-flops needed to hold the current state.
As mentioned before, it is not wise to just blindly partition your FSMs arbitrarily. It is important to try to look for patterns and recognize “regions of operation”. Then, try to find transitions in and out of this regions which are relatively simple (ideally one condition to go in and one to go out). This means that sometimes it pays to include in a “region” one more state, just to make the transitioning in and out of the “region” simpler.
Use this technique. It will make your FSMs easy to debug, simple to code and hopefully will enable you to introduce low power concepts more easily in your design.