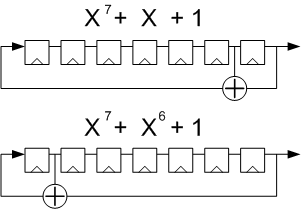
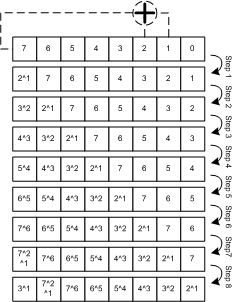
I get a lot of emails from readers from all over the world. Many want me to help them with their latest design or problem. This is OK, after all this is what this site is all about – giving tips, tricks and helping other designers making their steps through the complex world of ASIC digital design.
Many ask me for solutions directly in Verilog or VHDL. Although this would be pretty simple to give, I try to make sure NOT to do so. The reason is that it is my personal belief that thinking of a design in terms of Verilog or VHDL directly is a mistake and leads to poorer designs. I am aware that some readers may differ, but I repeatedly saw this kind of thinking leading to bigger, power hungry and faulty designs.
Moreover, I am in the opinion that for design work it is not necessary to know all the ins and outs of VHDL or Verilog (this is different if you do modeling, especially for a mixed signal project).
Eventually we all have to write code, but if you would look at my code you’d see it is extremely simple. For example, I rarely use any “for” statement and strictly try not using arrays.
Another important point on the subject is for you guys who interview people for a new position in your company. Please don’t ask your candidates to write something in VHDL as an interview question. I see and hear about this mistake over and over again. The candidate should know how to think in hardware terms; It is of far lesser importance if he can generate some sophisticated code.
If he/she knows what he is aiming for in hardware terms he/she will be a much better designer than a Verilog or VHDL wiz who doesn’t know what his code will be synthesized into. This is btw a very typical problem for people who come from CS background and go for design.